Automatic file splitting on S3 buckets at zero cost
For the last few years that I have been working with AWS I've been experimenting with different features that are available to the platform. One important feature of the aws s3 cp command though really escaped me, until I had the need for it. We were working on a project that required large volumes of data to be processed during an initial boostrapping process. Typically we use the AWS CLI to copy large volumes of data from on-premise infrastructure to S3 buckets and when we need to process the data in batches we split it all before the upload. If the data is already on S3 then we need to download it of course and then split it which is not ideal when clients deliver to your S3 buckets a few GBs.
First thing that came to mind is to build an AWS Lambda that can actually do all this automatically but then the data needs to be downloaded and that presents in itself scaling challenges that come with a certain cost. While running some web searches on the subject, I discovered that hidden within the official AWS documentation, is a feature of the copy command, that actually supports data streaming without the need to download anything. This is a piece of functionality that is not so much "advertised" and appears only at the bottom of the documentation.
The "magic" dash in the copy command
The aws s3 sp command supports just a tiny flag for downloading a file stream from S3 and for uploading a local file stream to S3. This functionality works both ways and makes the streaming of data in and out of S3 pretty easy. In a typical download example it looks like this:
aws s3 cp - s3://mybucket/mybigfile.txt
This - is the magical extension of the copy command and the one that allows us to deploy a very lightweight lambda to do the file splitting.
How does the file split work?
The splitting process is pretty simple once you get to grips with the copy command.
- We create source and target buckets
- We retrieve a file stream from the S3 source bucket
- Then we look at the line count of the input stream and separate a chunk every N lines which is just a variable number
- We generate a new file from the latest chunk of data
- And subsequently upload that stream to this new file
NOTE:If you want to use the Lambda to do the file splitting automatically, you need to make sure you have two separate buckets. If not, subsequent events will get triggered every time a split file lands on the source and you end up with recursive functionality.
You would probably think that this requires quite a bit of code to execute but Unix come to the rescue. We already have the copy command from AWS and to split the data we can use the split command which is a well known Unix tool. By using the filter flag on the split command we can create the new files that will be created on the target S3 bucket. The filter gives us a new filename for every chunk of data being processed.
An example of the full command can be seen below using. You could easily embed this in any script and simply pass as arguments the file input and the output bucket. The output of the filter argument is the $FILE variable that essentially assigns a new name to our source for every stream being processed.
aws s3 cp s3://mybucket/bigdatafile.csv - | split -d -l ${LINECOUNT} --filter "aws s3 cp - \"s3://splitbucket/bigdatafile_\$FILE.csv\"
Setting up the AWS Lambda
The next step is to actually set up an AWS Lambda that will get triggered when a large file lands on S3. Typically you would write a bit of Python or Javascript code that runs your bash script but I wanted to find a simpler solution that just runs my script. Within the AWS Lambda world there is a feature called Layers. Layers essentially give you extra code and features by adding them when you first build your Lambda function.
You can find a useful repository in Github here that essentially gives you full access to a Bash layer for an AWS Lambda. This repo has all the instructions necessary to set up the Bash layer but in a summary when you create your function you need to provide the Layer ARN seen below.
arn:aws:lambda:<region>:744348701589:layer:bash:8
Once your layer is set up and your function is ready for code you need to create the trigger. I am listening to all event types in this example.
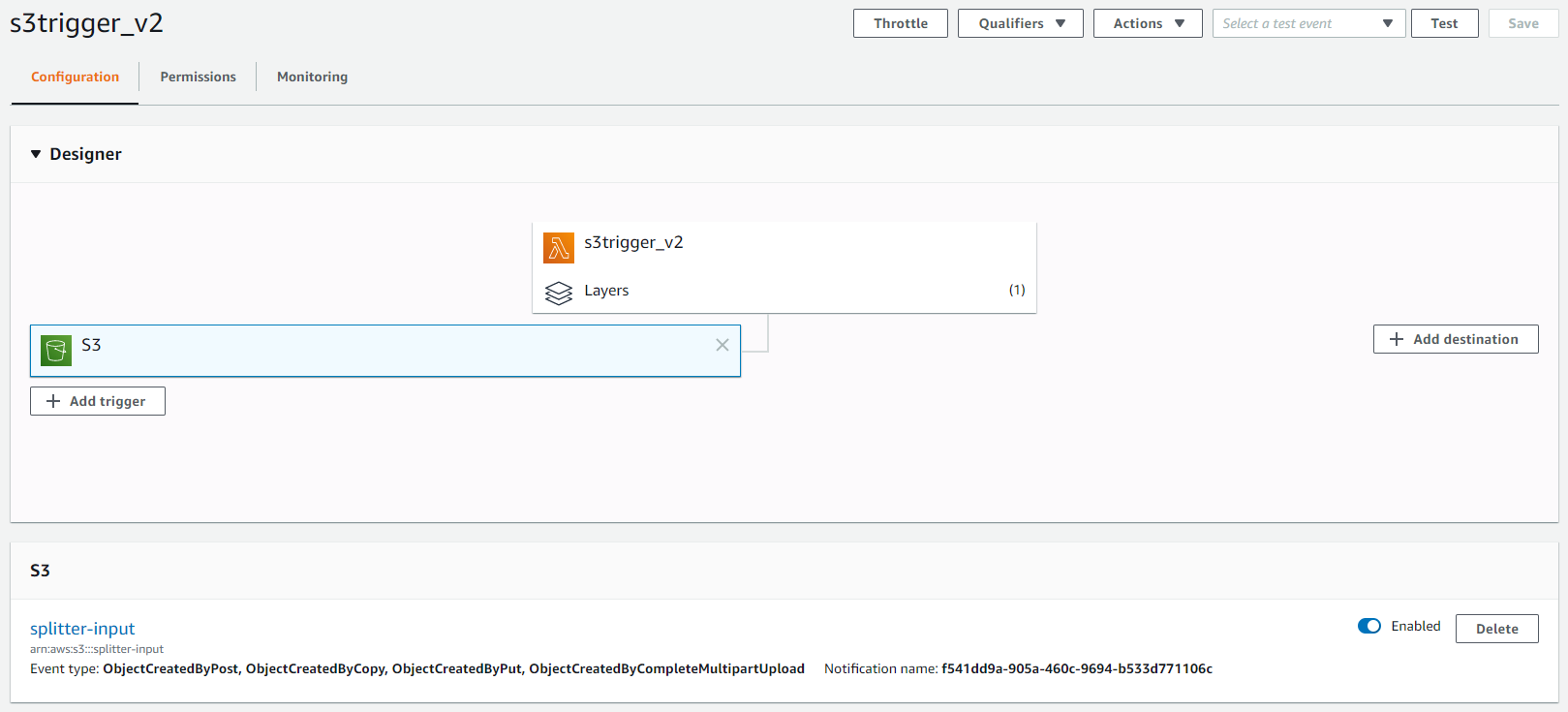
Then you only need to create a single script that will perform the task of splitting the files. Within the bash script we listen to the EVENT_DATA json which is sent by S3. Using the jq Unix tool we lookup the json for the S3 source bucket and filename. In the example below we use a linecount of 100K lines but this could also become a parameter that is passed to the Lambda eventually. The last thing to do is to specify the Lambda's Handler settings the handler function below.
handler () {
set -e
# Event Data is sent as the first parameter
EVENT_DATA=$1
S3_BUCKET=$(echo $EVENT_DATA | jq '.Records[0].s3.bucket.name' | tr -d \")
FILENAME=$(echo $EVENT_DATA | jq '.Records[0].s3.object.key' | tr -d \")
LINECOUNT=100000
# Start processing here
INFILE=s3://"${S3_BUCKET}"/"${FILENAME}"
OUTFILE=s3://splitter-output/"${FILENAME%%.*}"
echo $S3_BUCKET, $FILENAME, $INFILE, $OUTFILE
echo "Starting S3 File Splitter using line count of "${LINECOUNT}" lines"
echo "Splitting file: "${INFILE}" ..."
FILES=($(aws s3 cp "${INFILE}" - | split -d -l ${LINECOUNT} --filter "aws s3 cp - \"${OUTFILE}_\$FILE.csv\" | echo \"\$FILE.csv\""))
# This is the return value because it's being sent to stderr (>&2)
echo "{\"success\": true}" >&2
}
Function execution and Cloudwatch monitoring
Once the function starts running it will output all log messages to the Cloudwatch logs associated with the Lambda that are easily accessible. In the logs you can see when the function starts processing, echo any parameters being passed or processed and any errors that might occur. The screenshot gives you a glimpse of the output of this function. For the input file used in this example, total execution time was 73 seconds.
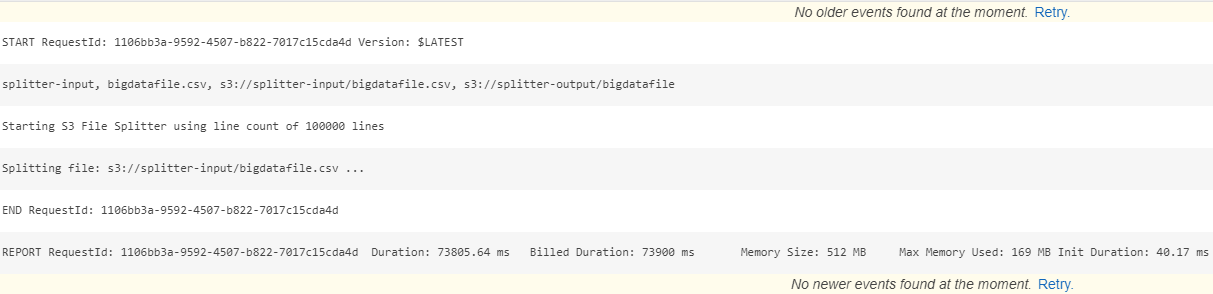
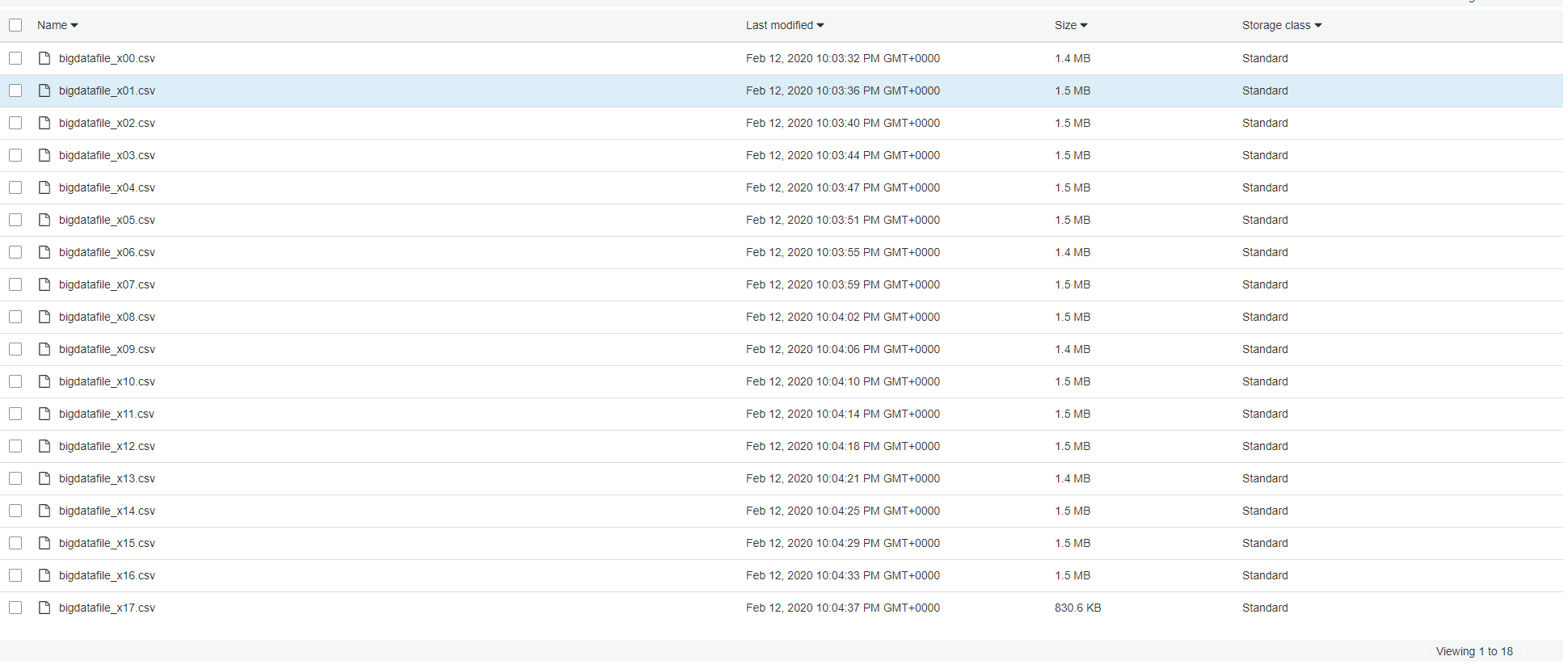
You now are ready to start processing big files automatically and generate smaller chunks that could be utilised in parallel processing scenarios. THe input file I dropped into the source S3 bucket contained 1.7 million records and with a line count of 100K I expect to see 17 files being generated in total. In the screenshot below you can see the final outcome.
AWS Costs
Running Lambda functions like this, doesn't really anything at all, since in most scenarios you are well within the boundaries of the free tier. If you were in a production environment, processing non-stop very large files then there would be some cost. This would still be way below what you would pay if you had to provision EC2 instances in order to download the files, split them locally and then upload the results.